
元学习下基于多区域深度特征融合的多类型图像质量评估
论文主体思路
论文主要贡献
- 本文提出了一种基于元学习(MMQA)下多区域深度特征融合的多类型图像质量评估方法。首先,我们利用结构信息的差异来筛选出显著和非显著区域。其次,设计深度多流网络,模拟人类视觉系统(HVS),综合考虑和融合显著区域、非显著区域和整个图像中与质量相关的不同特征。第三,应用元学习,在面对新的图像类型时,快速学习和更新模型的参数。
- 设计了一个基于显著和非显著区域的深度多流网络来模拟HVS。该方法旨在用一种较轻的区域增强方法来提高模型性能。
- 为了模拟人类的学习风格,提出了一个元学习框架来总结先验知识。该模型可以利用先验知识快速处理多类型任务。
- 该方法可以满足多种类型的图像质量评估任务,具有泛化和鲁棒性的优点。该方法在多类型任务中的准确性也相当高。
非参考图像质量评估(NR-IQA)
- 非参考图像质量评估(Non-Reference Image Quality Assessment,简称NR-IQA)是一种无需参考图像(即未失真图像)的图像质量评估方法。与需要参考图像的全参考(Full-Reference,FR-IQA)方法不同,NR-IQA方法仅依赖失真的图像本身,评估图像的质量,无需原始的“金标准”图像。
Deep meta-learning
元学习(Meta-Learning),也被称为“学习如何学习”,是一种机器学习方法,它的目标是通过学习一些通用的知识和策略,使模型能够更快、更高效地适应新任务。元学习的核心思想是利用以往学习到的经验,来提高模型在新任务上的学习效率,尤其是当新任务的数据量较少时。
元学习的基本原理
元学习通常包括两个学习过程:
- 元层次学习(Meta-level learning):在元层次上,模型学习到一些高层次的知识,如如何快速适应不同的任务、如何优化模型参数、或者如何选择最适合当前任务的模型架构。这个阶段的学习是在大量不同任务上进行的,使模型能够积累“学习如何学习”的经验。
- 任务层次学习(Task-level learning):在任务层次上,模型使用元层次学到的知识快速适应某个具体任务,甚至只需少量样本(少样本学习)。这种任务通常是新出现的、之前未见过的任务。
MMQA流程概述
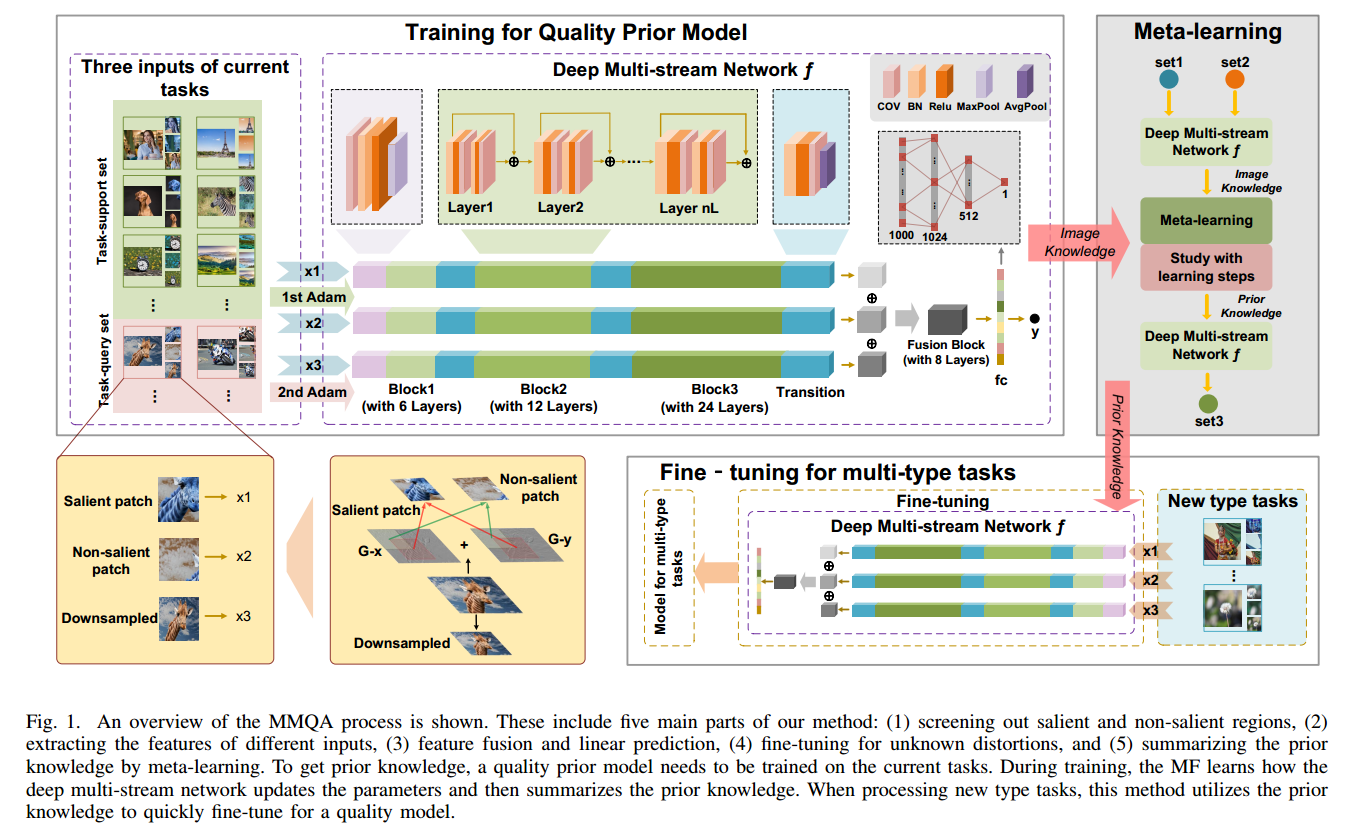
- 这包括我们方法的五个主要部分:(1)筛选出显著和非显著区域;(2)提取不同输入的特征;(3)特征融合和线性预测;(4)对未知扭曲进行微调;(5)通过元学习总结先验知识。为了获得先验知识,需要对当前任务训练一个高质量的先验模型。在训练过程中,MF学习深度多流网络如何更新参数,然后总结先验知识。在处理新类型任务时,该方法利用先验知识对质量模型进行快速微调。
显著区域和非显著区域

- 我们将显著性分数最大的图像块作为显著区域,最小的图像块作为非显著区域。为了可视化该方法在筛选显著区域和非显著区域方面的效果,我们选择KADID中的一些图像作为示例,分别使用红色和绿色背景框定位显著区域和非显著区域。具体情况如图2所示。
显著性分数计算

- 为了突出不同块与整个图像之间的关系,该方法使用显著分数来表示局部变化与全局信息之间的相关性。数字i块的显著性分数由式3计算。
Extracting features of different inputs
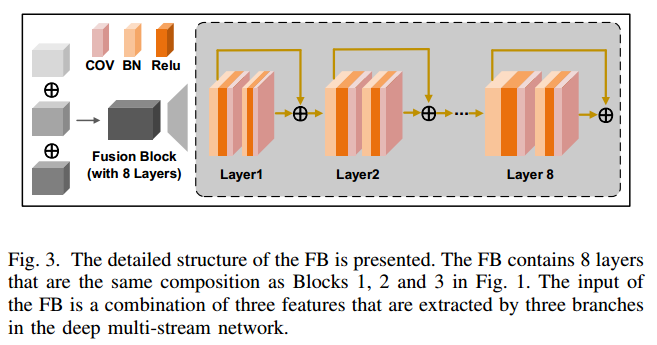
- 该方法将显著区域、非显著区域和整幅图像作为输入。通过兼顾整体特征,网络可以增强对关键要素的关注。在特征提取过程中,感受野发生变化,逐渐呈现出不同大小的特征表征。随着网络的发展,浅层特征和深层特征之间的关系将逐渐减弱。为了更好地连接不同深度的特征信息,我们设计了一个层间交互更频繁的网络,其中每个分支交替由三个块组成,交替由三个过渡组成。
附录与补遗
合成失真和真实失真
合成失真:这是通过人为的方式在图像上引入的失真,常见于传统的IQA数据集。常见的合成失真包括:
- 压缩失真:如JPEG压缩、JPEG2000压缩等,会导致图像出现块效应或模糊。
- 模糊:通过添加高斯模糊、运动模糊等来模拟相机抖动或对焦不准等情况。
- 噪声:添加高斯噪声、椒盐噪声等来模拟图像的传输或传感器噪声。
- 色偏:通过改变图像的色彩通道来模拟光线或色彩失真。
真实失真:这些失真是由于实际拍摄或传输过程中的各种不可控因素造成的,不是人为合成的。真实失真通常更加复杂且多样化,难以精确模拟,常见于实际应用场景中。真实失真包括:
- 传感器噪声:由成像设备本身的限制引起的噪声,例如在低光照环境下拍摄的图像。
- 透视失真:由于拍摄角度或镜头畸变引起的失真。
- 光线失真:如过曝或欠曝的情况。
- 其他复杂失真:如多种失真同时存在,或由于设备、传输、环境等综合因素导致的失真。
可以参考的图例
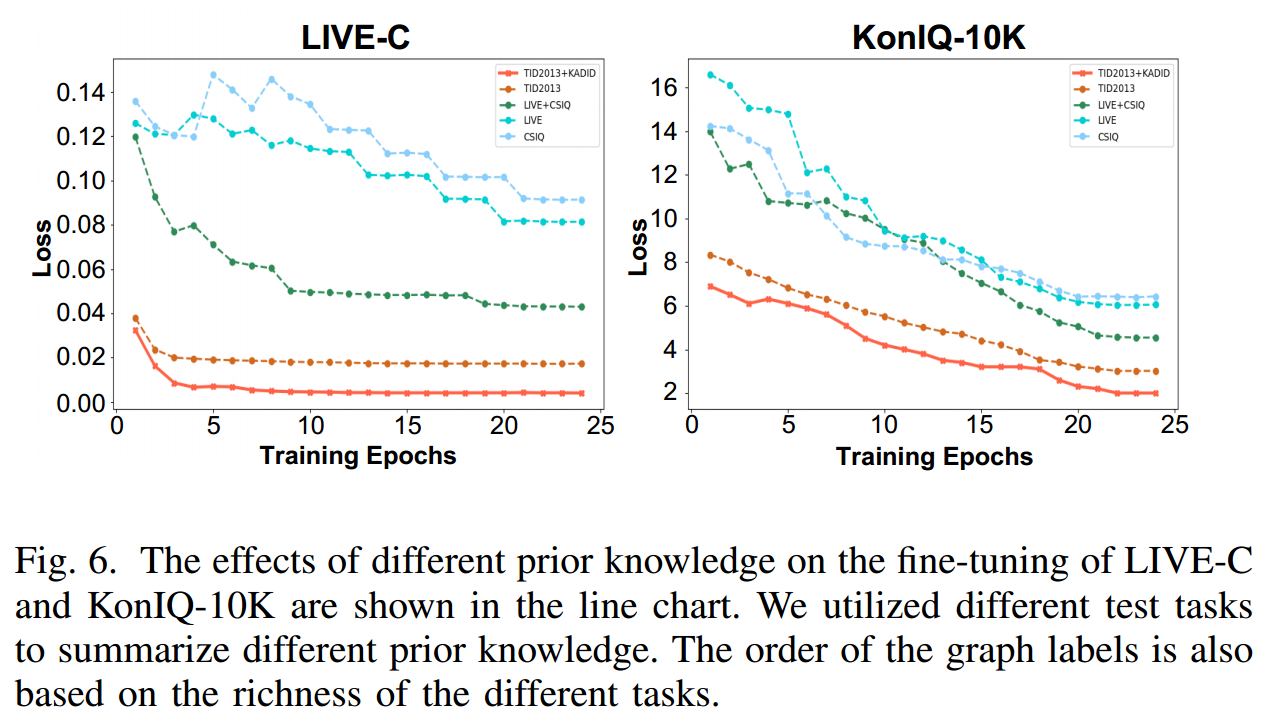
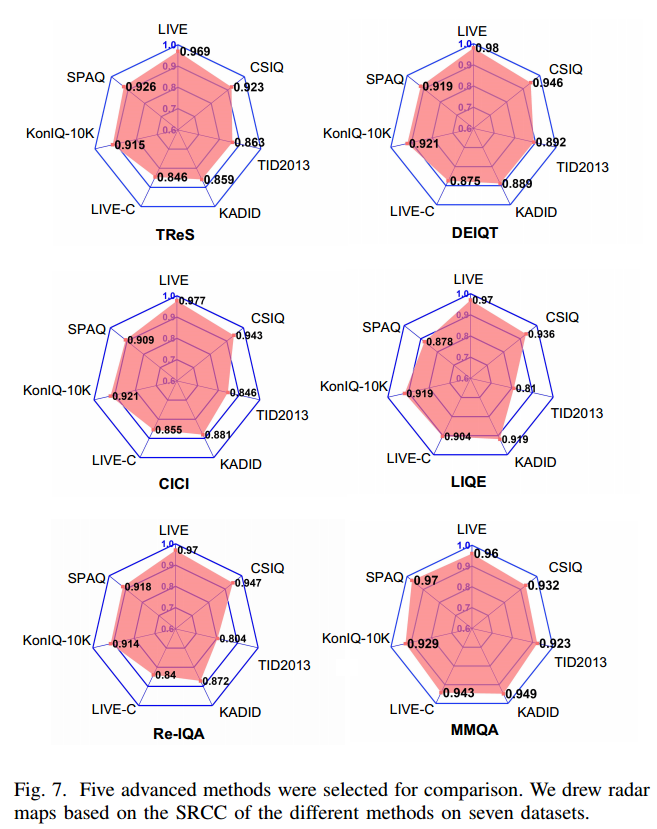
论文中可以引用的部分
关于NR-IQA
- 早期基于深度学习的NR-IQA使用深度卷积神经网络(DCNNs)捕获深度特征,并在IQA任务中表现良好。Kang等人[39]描述了一种基于卷积神经网络(CNN)的方法,其中整个网络由一个最大池化层、两个完全连接的卷积层和一个输出节点组成。该网络将特征学习和回归结合到一个优化过程中,形成一个更有效的IQA模型进行训练。Bosse等人[40]设计的特征提取网络具有明显的深度。它采用端到端训练模式,由10个卷积层、5个特征提取池化层和2个全连接回归层组成。该模型在学习图像的局部信息方面更加稳定和准确。这些方法旨在提高特征提取的能力。因此,他们可以捕捉失真和质量之间的关系,在合成失真。但这些方法在处理较为复杂的真实失真时表现不佳,泛化程度有待提高。这使得它们无法处理具有多类型任务的应用程序场景。
- 一些多尺度方法通过丰富特征信息来提高性能。Zhang等[41]提出了一种利用不同深度网络提取特征的方法,使用不同的浅层特征作为输入,增强对语义信息的分析。然而,多流网络的作用并不能得到合理的解释。Hu等[22]利用图像的空间信息和梯度域信息综合表达畸变信息。然而,模型的鲁棒性有待提高。此外,Zhang等人[42]利用文本信息作为新的尺度来帮助模型捕捉失真细节并基于余弦相似度计算联合概率。虽然可以增强模型定位重要区域畸变的能力,但该方法依赖于大量的标签数据。Karimi等人[26]检测了显著区域是如何被保留的,以及相关特征产生了多少几何畸变。Feng等人[25]引入了一种高效的特征学习框架。使用从未标记图像的显著区域提取的图像块来学习稀疏编码字典。这些方法通过添加显著区域来提高模型的性能,但无法分析显著区域、非显著区域与全局特征之间的相关性。由于这个缺点,语义分析不太完整。
- 为了更好地研究真实失真中的语义信息,更多的方法注重分析图像之间的深层关系。Su等[43]提出了一种自适应超网络架构来盲评估野外图像质量。在提取图像语义后,使用超网络自适应构建感知规则,然后使用质量预测网络进行感知。该方法通过增强语义分析和参数共享,在真实失真方面取得了进一步的效果。随着Transformer的广泛应用,结合Transformer[44] -[48]的NR-IQA方法有了新的发展。Ke等[45]提出了一种多尺度图像质量转换器(MUSIQ)来处理不同尺度的图像失真。此外,针对图像块位置嵌入问题,他们提出了一种新的基于哈希的二维空间嵌入和基于哈希的尺度嵌入,以支持多尺度表示中的位置嵌入。Golestaneh等[46]提出了一种基于CNN和自注意机制的NR-IQA模型,可用于从图像中提取局部特征和全局语义信息。Qin等人[47]引入了一种Transformer Decoder,可以从不同角度对感知到的信息进行细化。同时,引入了一种新的注意面板机制来模拟人的主观评价行为。Saha等人[48]提出了一种混合方法,训练两个独立的编码器,在无监督环境中学习图像的高级语义和浅层特征。
关于文献
题目及期刊
题目:Multi-type Image Quality Assessment based on Multi-region Deep Feature Fusion under Meta-learning
期刊:无
作者信息
作者:朱顺(南京师范大学)
发表时间
日期:暂无
阅读时间
日期:2024年10月17日
开源代码及其它
GitHub:https://github.com/dart-into/MMQA (作者)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 YuJiang's Long Holiday!